Secure-by-Default Patterns for AI Content Pipelines
Secure-by-Default Patterns for AI Content Pipelines
AI content pipelines now touch customer data, brand voice, and production infrastructure. That makes them part of the security perimeter, not a side project for marketing ops. If you publish at scale with LLMs, you own the security consequences.
This editorial focuses on security-first design for AI editorial workflows—how to embed controls so safety is the default, not a bolt-on review step.
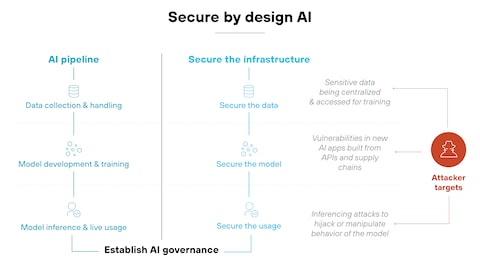
1. Treat the AI Editorial Stack as a Security-Critical System
Most teams still treat AI content tooling like a productivity app. In practice, it behaves more like a CI/CD pipeline: automated transforms, shared credentials, and direct paths to production.
In AI editorial pipelines, every prompt with write access is a deployment script with marketing veneer.
Secure-by-default starts by reframing the system:
- Asset: Content assets, brand voice, and editorial data are high-value targets.
- Threats: Prompt injection, data exfiltration, model misalignment, and supply-chain compromise.
- Impact: Silent reputational damage at scale is more likely than a single catastrophic breach.
Once you treat the pipeline as critical, you can justify real controls: identity, isolation, and auditability.
2. Design a Minimal-Exposure Architecture
The core architectural principle is simple: minimize what each component can see and do. That means isolating enrichment, generation, and publishing into distinct security zones.
A practical pattern for security-focused AI editorial pipelines:
- Frontend (authors & editors): No direct keys, only authenticated API calls.
- Orchestrator service: Owns routing to LLMs, logging, and rate limits.
- Redaction / anonymization layer: Scrubs PII, secrets, and sensitive identifiers before prompts.
- Provider boundary: External LLMs only see redacted, task-scoped context.
- Publishing adapter: Applies final checks and writes to CMS, Git, or marketing platforms.
Do not allow the model to write directly to production systems. The orchestrator should be the only component with that capability, and it should do so under strict policy.
3. Implement Principle-of-Least-Privilege for Language Models
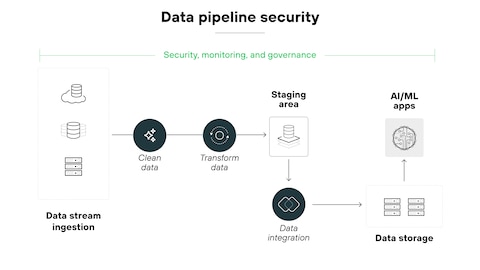
In most AI editorial stacks, the model sees everything: full customer stories, internal docs, drive folders. That is an anti-pattern.
Instead, apply least-privilege to context selection:
- Task-scoped retrieval: Use retrieval that is restricted to curated editorial corpora, not raw knowledge bases.
- Role-specific contexts: Separate corpora for product marketing, legal templates, and internal engineering docs.
- Time-bound caches: Expire prompt caches and temporary vectors aggressively.
- Redaction-first ingestion: Strip PII and secrets before content ever reaches your vector store.
When evaluating vendors, ask explicitly how they isolate tenant data, what logs they keep, and whether they train on your content by default.
4. Build Guardrails into the Editorial Workflow, Not Just the Model
Model-level safety filters are necessary but fragile. Secure-by-default means guardrails live in the workflow where humans and systems interact.
For an AI editorial pipeline, strong guardrails include:
- Template constraints: Prompts that enforce structure (sections, word ranges, disclaimers) instead of free-form generation.
- Policy-aware prompts: Every system prompt should reference explicit security and compliance rules, not vague “be safe” instructions.
- Automated content scanning: Run generated drafts through PII detectors, link checkers, and toxicity classifiers before editors see them.
- High-friction operations: Extra confirmation for actions that touch credentials, legal claims, or live customer names.
5. Secure Prompt and Plugin Surfaces Against Injection
Once your pipeline consumes external data (webpages, RSS feeds, briefs from third-party tools), you inherit prompt-injection risk. Attackers can plant instructions in content that your system later treats as authoritative.
Mitigation patterns:
- Content labeling: Explicitly label model-facing text as untrusted in the system prompt.
- Instruction segregation: Keep system and developer messages physically and logically separate from user content.
- Execution firebreaks: For actions like posting, editing DNS, or touching CRM data, require human confirmation even if the model requests them.
- Whitelist external tools: Allow only approved connectors, with clear per-tool permissions.
The goal is not to perfectly detect every malicious instruction. The goal is to design a pipeline where injected instructions lack the authority to do real damage.
6. Logging, Observability, and Incident Response for AI Editorial
Security AI editorial workflows must be observable. Without logs, harmful outputs and data leaks look like “bad copy” instead of security incidents.
At minimum, log:
- Who triggered a generation and which model version was used.
- What data sources were attached or retrieved.
- Which automated checks ran and their results.
- Who approved and pushed content live.
Then, define a lightweight incident playbook: how to roll back a post, revoke keys, rotate secrets, and notify affected stakeholders when AI-generated content crosses a security boundary.
7. Governance and Culture: Security as Editorial Quality
Secure-by-default patterns are only sustainable if they align with editorial incentives. The most effective framing: security is part of quality.
For founders and technical editors, that means:
- Include privacy, attribution, and claim-verification in your editorial checklists.
- Give editors visibility into which sections were AI-generated and which sources were used.
- Train authors to recognize when a prompt asks for more access than the task requires.
- Treat near-miss security issues as postmortems, not blame games, and update prompts and workflows accordingly.
Security AI editorial practices will not mature overnight. But the organizations that normalize secure-by-default patterns today will compound trust, avoid brand-damaging incidents, and maintain the freedom to experiment with more powerful models tomorrow.
Clarity in writing comes from structure, not length.